Summary
This is the first part of a multi-post exploration of the ways in which procedure variables, function pointers (call them what you will) are implemented in managed execution systems such as .NET and the JVM. Particular implementation details for both .NET and the JVM type systems place limitations on the implementation of this functionality.This first post briefly reviews the idea behind procedure types, and the implementation mechanisms on the .NET and JVM platforms.
The second part looks at various ways to get the same semantics on the (pre-version 7) Java Virtual Machine. This second part also discusses the limitations of both managed execution systems in implementing procedure types.
A final part will look specifically at how the new functionality in JDK v7 changes the landscape, removing one of the limitations. This final part will also look at implementations based on use of lambda abstractions - available on the .NET platform currently, and coming soon in version-8 of the Java.
Background
Many programming languages have a construct that allows a variable to be declared as containing a value that denotes a particular procedure value. The procedure denoted by the variable may be invoked by calling the procedure value. Such procedure values may be created, by associating the new value with some named procedure, and values may be copied and assigned using the conventional syntax of the particular language.Compilers implement these constructs, in the simplest case, by making the procedure value be of pointer size, and using the entry-point-address of the bound procedure as the value. This implementation mechanism is explicit in ANSI C, where such values are called "function pointers". Languages that permit nested procedures to be used as procedure values are a little more complicated, since the called procedure needs to be given access to the stack frames of its enclosing procedures. However, that circumstance is mainly of historical and theoretical interest nowadays.
Typical machine architectures have two distinct subroutine call instructions, call and calli, which respectively call a method by its symbolic name, and indirectly call the method that the entry point address of which has been loaded into some chosen register.
The calling sequence for a regular call goes something like this -
- load up the arguments to the call
- call the named procedure
- load up the arguments to the call
- load the procedure variable value into the chosen register
- calli through the chosen register
Procedure variables are thus strongly typed, and programming languages that provide procedure variables may allow such procedure types to be named in the usual way. In Component Pascal, the syntax looks like this -
TYPE NoArgToInt = PROCEDURE( ) : INTEGER;
Which gives a name to a type of procedures that take no arguments, but return an integer. We may now declare variables of this type -
VAR p1, p2 : NoArgToInt;
which declares two variables of the named procedure type. We could just have easily left the procedure type unnamed, and declared the variables as being of some anonymous procedure type -
VAR p1, p2 : PROCEDURE( ) : INTEGER;
with the same effect.
When the compiler emits instructions to construct a new procedure value it will check that any named procedure that is being bound to a new value has the correct argument number and type and conforming return type.
Now, a little thought will convince the reader that although it may be convenient to have a name for a procedure type, but two procedure types should b e compatible provided that they have the same call signature. Thus such languages have type compatibility rules for procedure values that implement structural compatibility, that is "two procedure types are the same type if they have the same argument number and type, and the same return value (or lack of return value)".
This observation, regarding structural compatibility, does not even arise in ANSI C. Function pointer types are denoted by an "abstract declarator" that declares only the parameter types and the return type. The abstract declarator for our NoArgToInt type would be -
int (*)( )
that is "pointer to function taking no arguments and returning int.Implementing Procedure Types on .NET
Implementing procedure types on .NET is fairly straightforward. The built-in delegate type of the framework is almost exactly what we need. Consider the following C# progam fragment -
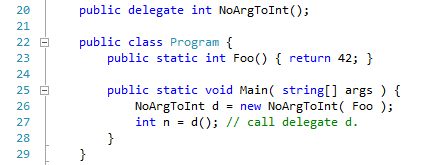
At line 20 a new delegate type is defined, with the "no args, returns int" signature. At line 23 a static method Foo is defined, with a compatible signature. A new instance of the delegate type is defined at line 26, taking Foo as its bound method value. The method is invoked via the delegate value at line 27.
There are a couples of wrinkles about .NET delegates that I am ignoring for the moment. Delegates may be bound to either a static method, as in this example, or bound to an instance method. In the case of an instance method the "this" reference is supplied at delegate creation time. A delegate may thus be thought of as encapsulating two data: a pointer to the method entry point, and a copy of the receiver to which the method is to be applied.
Not exactly what we wanted
The only real defect of the .NET delegate, as a feature to implement procedure values, is the lack of structural compatibility. Suppose an application depends on two existing libraries, both of which have API calls with parameters of delegate types, and use different names for (say) the NoArgToInt signature. Now the names of the delegate types are baked into the APIs, and although our method Foo is compatible with each, the delegate values are not assignment compatible. This is extremely annoying, since it is clear that the same semantic analysis inside the compiler that decides that Foo is compatible with each of the two delegate types can also decide that values of the two types are compatible with each other. (There was a proposal to move to structural compatibility for delegate types in V2 of the framework, but it didn't make it into the release.)
The .NET version of GPCP essentially produces the same machine code for Procedure Types as a C# compiler would for the equivalent delegate-based program. The semantics are not exactly as described in the language report, because of the lack of structural compatability of values.
Implementing Procedure Types on the (pre-V7) JVM
On the JVM the starting point is even further back, as the JVM has nothing equivalent to a built-in delegate type. Since the platform does not give us the primitive construct that we need, we must build it ourselves. Here is the Java program that we need to construct to get semantics equivalent to the C# example above.

It may seem that if a program has many, many different procedure value instances that the namespace is going to become cluttered with lots of "single use" sub-classes, and that an anonymous class would be nicer. This is true of course, but the namespace is still cluttered, it is just that the clutter is with names that the compiler chose for you. And, yes, the names will be names that would be illegal in your Java program, so that these names will not clash with anything that the programmer might have named herself.
It would also be possible to define an interface base type, rather than an abstract type to hold procedure values, with similar results.
Notice that the Java mechanism has the same problem with compatibility of types as the .NET framework. Two variables are assignment compatible if they are derived from the same abstract base type.
Preview of part II.
In part two of this series, I shall look at alternative mechanisms for implementing procedure types. In particular there are interface base types (rather than an abstract base class), there is the use of runtime reflection, and the new MethodHandle types that appeared in Java SE version 7. I also will report a performance shoot-out, so that users may make informed choices between the various mechanisms.
No comments:
Post a Comment