Summary
This is part two of a short series on the implementation of procedure types and variables on top of the .NET framework, or the Java Virtual Machine. In this part I consider alternative mechanisms for implementing procedure types on each platform.
The .NET Framework
On the .NET framework the delegate type appears to be the obvious choice. After all, the construct was designed for exactly this job, and as the basis of the .NET event-handling model. However, there is nothing to stop us from using a single-member base class or interface, just as we are (or rather were) forced to do on the JVM. Which is better?
The question of which mechanism is better is not one that may be answered on the basis of inclination or traditional prejudice. What we need is some evidence, and to be sure evidence from a range of different usage patterns. However, let us start with the simple case of simple procedure (static method) with a simple signature.
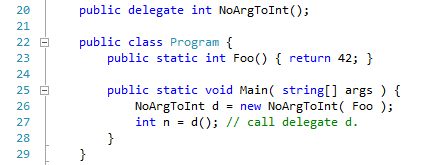
 Here are three ways of calling the static method Hello, using three different mechanisms for representing procedure values. At line 23 we declare the StringToVoid delegate type, and at line 14 we create a instance of the delegate type that wraps the method Hello.
Here are three ways of calling the static method Hello, using three different mechanisms for representing procedure values. At line 23 we declare the StringToVoid delegate type, and at line 14 we create a instance of the delegate type that wraps the method Hello.
At line 26 an interface is declared with a single member "Invoke" of the string to void signature. This interface is implemented by the IWrapHello class, that wraps the Hello method. Essentially the same semantics are achieved by the abstract class S2V and its subclass WrapHello at line 31. The three "function values" are created at lines 14 .. 16, and are each called, in turn, in the following three lines.
So, a compiler could use any of these three mechanisms to represent types and values for static methods. The amount of generated IL would be very similar each case, and the details of the naming of the wrapper types would be hidden in the implementation. But what are the comparative overheads of these three mechanisms?
Four different ways of implementing procedure variables were tried, with two different micro benchmarks. The first test was very simple: the static method that was encapsulated in the variable took a string argument and returned its length. This variable was called in a loop which repeated about 10^6 times. Some idea was to make the body of the wrapped method so simple that small differences in the calling machinery would still be significant. The results are shown in the left column of the table.
The results seem to indicate that the .NET delegate mechanism has a small time advantage over both the concrete sub-class overriding an abstract method in a single-member class, or a class implementing the single member of an interface. The other thing to note is the overhead of reflective invocation. About two orders of magnitude, for a simple method body.
Of course, with one must be a little careful with a JIT compiler, as it may do special magic on loops that repeat many, many times. The second example is designed to be slightly more realistic. The code uses a rather unusual coding pattern for implementing a finite state automaton (FSA). The state variable is a procedure variable holding the "nextstate" function. The function is fed the next symbol, in this case a single bit and returns the nextstate function corresponding to the next state of the FSA. The whole thing is attached to a pseudo-random binary sequence generator which repeats every (2^19 -1) steps. The details of generators of this kind are given at Wikipedia Linear_feedback_shift_register. In this case a Galois implementation was used. This generator produces a string of 18 zero bits only once every cycle, which is what the FSA searches for. The state is updated at every step, in an apparently random fashion, in an attempt to defeat any clever prediction strategy of the JIT. The results are shown in the right hand column of the table. It may be seen that our three favored strategies have very comparable results.
The final column of the table, just for the record, lists the compatibility semantics of the procedure variable containers. All three of our favored mechanisms enforce name-compatibility, which is not what we really want. What we want is compatibility based on equality of Signatures of the encapsulated method. Reflective invocation of the MethodInfo value has the right semantics, but the loss of efficiency is overwhelming.
At line 26 an interface is declared with a single member "Invoke" of the string to void signature. This interface is implemented by the IWrapHello class, that wraps the Hello method. Essentially the same semantics are achieved by the abstract class S2V and its subclass WrapHello at line 31. The three "function values" are created at lines 14 .. 16, and are each called, in turn, in the following three lines.
So, a compiler could use any of these three mechanisms to represent types and values for static methods. The amount of generated IL would be very similar each case, and the details of the naming of the wrapper types would be hidden in the implementation. But what are the comparative overheads of these three mechanisms?
 |
| .NET timing for various procedure variable implementations (see text). |
The results seem to indicate that the .NET delegate mechanism has a small time advantage over both the concrete sub-class overriding an abstract method in a single-member class, or a class implementing the single member of an interface. The other thing to note is the overhead of reflective invocation. About two orders of magnitude, for a simple method body.
Of course, with one must be a little careful with a JIT compiler, as it may do special magic on loops that repeat many, many times. The second example is designed to be slightly more realistic. The code uses a rather unusual coding pattern for implementing a finite state automaton (FSA). The state variable is a procedure variable holding the "nextstate" function. The function is fed the next symbol, in this case a single bit and returns the nextstate function corresponding to the next state of the FSA. The whole thing is attached to a pseudo-random binary sequence generator which repeats every (2^19 -1) steps. The details of generators of this kind are given at Wikipedia Linear_feedback_shift_register. In this case a Galois implementation was used. This generator produces a string of 18 zero bits only once every cycle, which is what the FSA searches for. The state is updated at every step, in an apparently random fashion, in an attempt to defeat any clever prediction strategy of the JIT. The results are shown in the right hand column of the table. It may be seen that our three favored strategies have very comparable results.
The final column of the table, just for the record, lists the compatibility semantics of the procedure variable containers. All three of our favored mechanisms enforce name-compatibility, which is not what we really want. What we want is compatibility based on equality of Signatures of the encapsulated method. Reflective invocation of the MethodInfo value has the right semantics, but the loss of efficiency is overwhelming.
The JVM Framework
The MethodHandle Class, and JSR292
Meanwhile, in the Java world, Java SE Version-7 introduced a number of changes designed to benefit all those dynamically typed languages that have been implemented to run on top of the JVM. The process of proposing and implementing the changes took several years, and anyone interested in the process should Google "JSR292" to see the history.
In essence, the JSR 292 changes introduced one new byte code instruction, invokedynamic, and a few new classes in the library. MethodHandle and MethodType are the two new classes of interest here, and both belong to the package java.lang.invoke.
I shall say nothing this time about invokedynamic, although it is an interesting topic for another day. Despite the impetus for the new instruction having come from the dynamically-typed language community, it turns out to be an ideal method for the implementation of the Lambda Abstractions that will launch with Java SE Version-8. However the two new classes are directly relevant to this discussion.
MethodType is a descriptor for a method signature. The object factory for the class is passed arguments with the Class objects for the return type and the parameter types. MethodHandle is wrapper for a method value. Objects of the type may be created by a factory method that is passed a Class object, the name of a method within that class, and a MethodType object. The returned handle encapsulates the matching method. If the MethodInfo object of the target method is known, presumably by reflection, then the corresponding method handle is created by a call to the amusingly named "java.lang.invoke.unreflect".
Here are the corresponding results of the two test programs.
 |
| JVM timing for various procedure variable implementations (see text).
All of these measurements, for both frameworks, were performed on a four year old Intel E8400 processor running Windows-7 (32-bit). You may note that the MethodHandle mechanism has low overheads, with similar per-call overhead to the previous implementation methods once the method bodies do any computation. The rather lower overhead of reflective invocation of a java.lang.Class.method compared to that for a System.Reflection.MethodInfo is an interesting piece of trivia to store away in a spare neuron.
The Anonymous interface method row of the table is interesting, as this performs well on the example using the nextstate-function pattern. The gain here is that there is one less method call in the chain. In effect, the anonymous method "inlines" the body of the next-state function rather than calling the next-state function.
A simple table-lookup implementation of the FSA is included here, as a reality check.
So here is a tentative conclusion: The MethodHandle mechanism has comparable overhead to the other implementations of procedure variables. And, as a bonus, it has the sensible structural-compatibility semantics that we would expect procedure types to display.
About the Next Episode
In the final episode of this series I shall look a bit closer at the case of method values that encapsulate both a method, and a receiver ("this" value) to invoke the method on. I shall also look at using lambda abstractions to realize similar coding patterns to the use of procedure/method variables.
Late-Breaking News
My MethodHandle-based FSA benchmark crashes the Hotspot(r) Compiler for Windows X64. It runs fine on the 32-bit X86 Hotspot compiler. On X64 it runs fine with java -Xint, or if the run is too short for Hotspot to attempt heroic optimizations. Watch this space for further developments.
|